Diffuse on Gaussian Mixtures#
Gaussian Mixture Models (GMM) have the advangtage of admitting closed form solution for the diffusion processes and the for the posterior sampling task of inverse problems. In this Tutorial we will show how to use Gaussian Mixtures to test Diffuse and illustrate its core components.
Gaussian Mixture Model (GMM)#
A GMM represents a probability distribution as a weighted sum of \(K\) Gaussian components:
Where:
\(w_i\geq0\), \(\sum_iw_i=1\) (mixture weights)
\(\mu_i\in\mathbb{R}^d\) (component means)
\(\Sigma_i\in\mathbb{R}^{d\times d}\) (component covariance matrices)
In the following, we introduce the helper functions MixState and pdf_mixtr to create and evaluate GMMs, and sampler_mixtr to sample from them.
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
from myst_nb import glue
# Import GMM utilities
from diffuse.examples.gaussian_mixtures.mixture import MixState, pdf_mixtr, sampler_mixtr
from diffuse.examples.gaussian_mixtures.initialization import init_simple_mixture
# Set random seed
key = jax.random.PRNGKey(42)
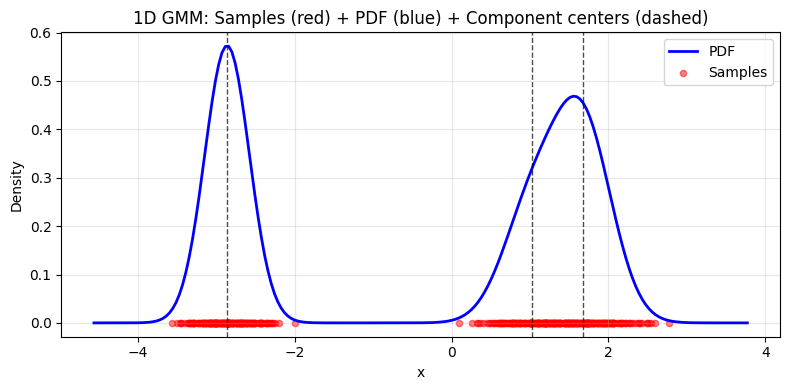
# Create 1D mixture
key, subkey = jax.random.split(key)
mix_state_1d = init_simple_mixture(subkey, d=1, n_components=3)
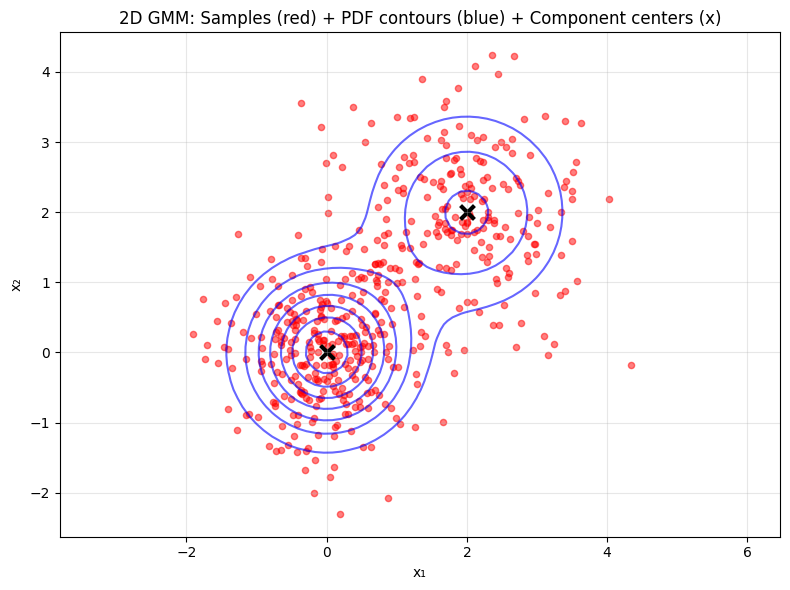
# Create 2D mixture by hand for clarity
weights = jnp.array([0.6, 0.4])
means = jnp.array([[0.0, 0.0], [2.0, 2.0]])
covariances = jnp.array([jnp.eye(2) * 0.5, jnp.eye(2) * 0.8])
mix_state = MixState(weights=weights, means=means, covariances=covariances)
# Sample from 1D mixture
key, subkey = jax.random.split(key)
samples_1d = sampler_mixtr(subkey, mix_state_1d, 500)
# Sample from 2D mixture
key, subkey = jax.random.split(key)
samples = sampler_mixtr(subkey, mix_state, 500)
print("Created 1D and 2D GMMs")
print(f"Sampled {len(samples_1d)} 1D points and {len(samples)} 2D points")
# Create PDF grid for 2D
x_range = jnp.linspace(-2, 4, 50)
y_range = jnp.linspace(-2, 4, 50)
X, Y = jnp.meshgrid(x_range, y_range)
grid_points = jnp.stack([X.ravel(), Y.ravel()], axis=1)
def pdf(x):
return pdf_mixtr(mix_state, x)
# Evaluate PDF on grid
pdf_values = jax.vmap(pdf)(grid_points)
pdf_grid = pdf_values.reshape(X.shape)
Created 1D and 2D GMMs
Sampled 500 1D points and 500 2D points
Closed Form Solution#
One of the key advantages of GMMs in diffusion modeling is that they admit closed-form solutions for both the forward diffusion process and posterior sampling in inverse problems. In this section, we demonstrate:
Forward Diffusion: How the GMM distribution evolves analytically under the diffusion SDE
Posterior Computation: How to compute the exact posterior distribution given measurements
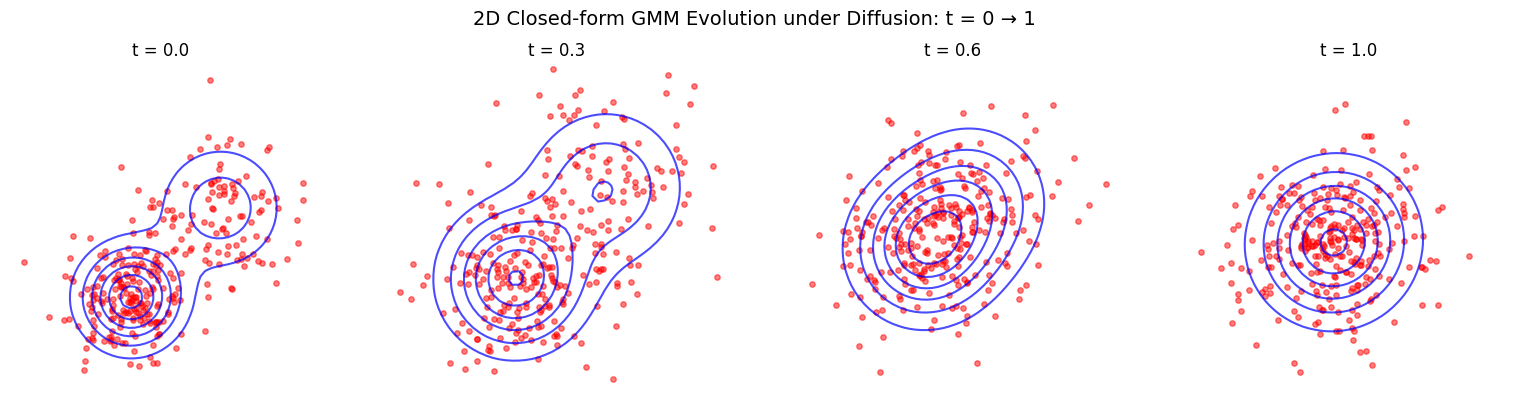
Forward Diffusion Evolution#
Given an initial data distribution \(x_0 \sim \text{GMM}\), i.e., \(p_0(x_0) = \sum_i w_i \mathcal{N}(x_0; \mu_i(0), \Sigma_i(0))\), where \(\sum_i w_i = 1\) and \(w_i \geq 0\), and a diffusion process defined by \(x_t = s(t) x_0 + \sigma(t) \varepsilon\), where \(\varepsilon \sim \mathcal{N}(0, I)\), the diffused distribution \(p_t(x_t)\) is also a Gaussian Mixture Model (GMM).
The diffused distribution is given by:
Where:
Mean: \(\mu_i(t) = s(t) \mu_i(0)\)
Covariance: \(\Sigma_i(t) = s(t)^2 \Sigma_i(0) + \sigma(t)^2 I\)
Weights: \(w_i(t) = w_i(0)\) (weights remain unchanged)
Note: The covariance expression assumes a general diffusion process. In specific diffusion models (e.g., variance-preserving diffusions like DDPM), the noise schedule may define \(\sigma(t)^2 = 1 - s(t)^2\), leading to \(\Sigma_i(t) = s(t)^2 \Sigma_i(0) + (1 - s(t)^2) I\).
These transformations are implemented in transform_mixture_params. It allows to compute the transformed parameters of the GMM at any time \(t\) given the initial parameters and the diffusion process with transform_mixture_params(mix_state, sde, t).
# Import diffusion components
from diffuse.diffusion.sde import LinearSchedule, SDE
from diffuse.examples.gaussian_mixtures.mixture import rho_t, transform_mixture_params
# Create SDE with linear schedule
beta = LinearSchedule(b_min=0.02, b_max=7.0, t0=0.0, T=1.0)
sde = SDE(beta=beta)
# Time evolution from t=0 to t=1
time_points = jnp.array([0.0, 0.3, 0.6, 1.0])
transform_at_times = jax.vmap(lambda t: transform_mixture_params(mix_state, sde, t))
mixtures_at_times = transform_at_times(time_points)
# Sample from all transformed 2D mixtures
keys = jax.random.split(jax.random.PRNGKey(123), len(time_points))
sample_at_times = jax.vmap(lambda k, mix: sampler_mixtr(k, mix, 300))
samples_at_times = sample_at_times(keys, mixtures_at_times)

Posterior Computation with Linear Measurements#
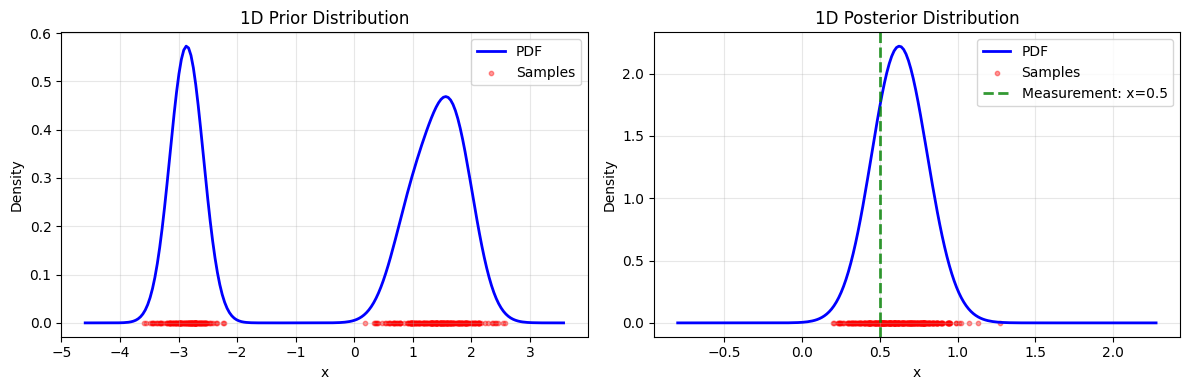
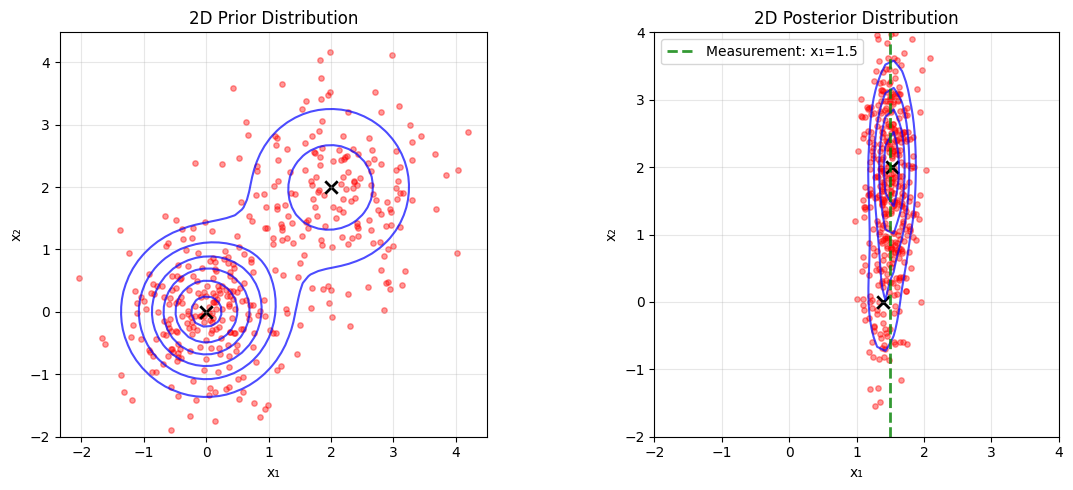
Given a prior distribution \(x \sim \text{GMM}\), i.e., \(p(x) = \sum_i w_i \mathcal{N}(x; \mu_i, \Sigma_i)\), where \(\sum_i w_i = 1\), \(w_i \geq 0\), and each component has mean \(\mu_i\) and covariance matrix \(\Sigma_i\), and a measurement model \(y = A x + \varepsilon\), where \(\varepsilon \sim \mathcal{N}(0, \sigma_y^2 I)\), the posterior distribution \(p(x|y)\) is also a Gaussian Mixture Model (GMM).
The posterior is given by:
Where:
Covariance: \(\bar{\Sigma}_i = \left( \Sigma_i^{-1} + \frac{1}{\sigma_y^2} A^T A \right)^{-1}\)
Mean: \(\bar{\mu}_i = \bar{\Sigma}_i \left( \frac{1}{\sigma_y^2} A^T y + \Sigma_i^{-1} \mu_i \right)\)
Weights: \(\bar{w}_i \propto w_i \times p(y|\mu_i, \Sigma_i)\), with normalization \(\sum_i \bar{w}_i = 1\)
Likelihood: \(p(y|\mu_i, \Sigma_i) = \mathcal{N}(y; A \mu_i, A \Sigma_i A^T + \sigma_y^2 I)\)
This conjugacy property makes GMMs particularly useful for testing and debugging diffusion-based inverse problems, as the posterior can be computed analytically at each step. In the following, we will compare the closed-form solution obtained with compute_posterior with the numerical solution given by the reverse-time SDE and approximate posterior sampling methods.
1D Measurement: y = [0.5] (observed x = 0.5)
2D Measurement: y = [1.5] (observed x[0] = 1.5)
Unconditional Generation#
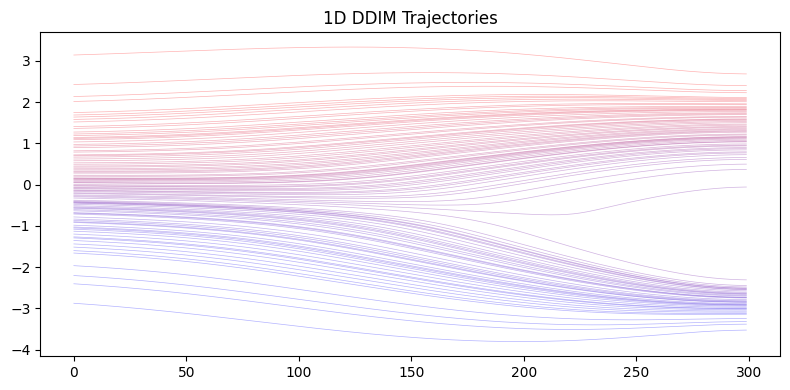
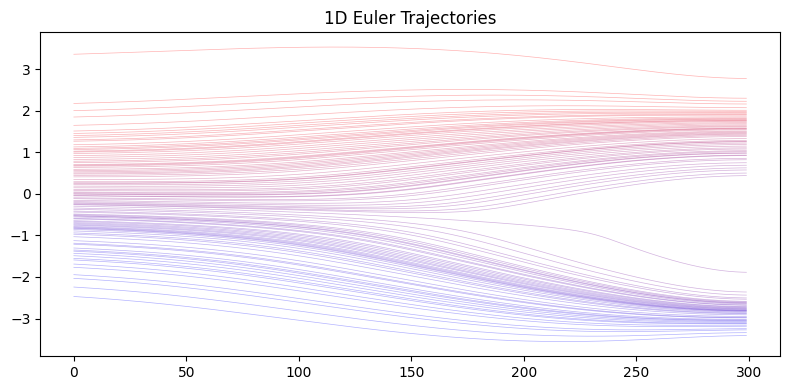
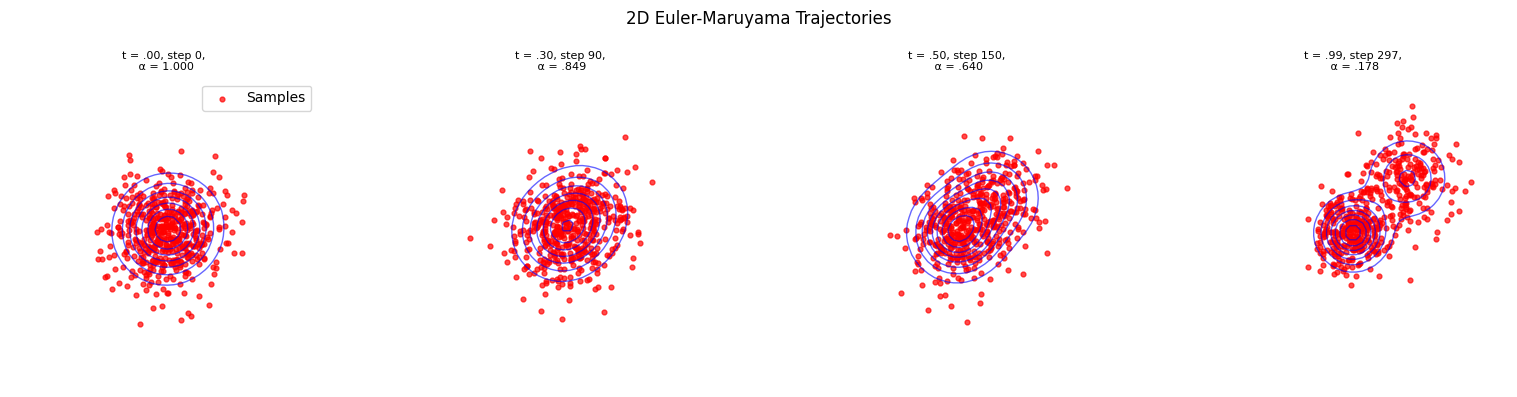
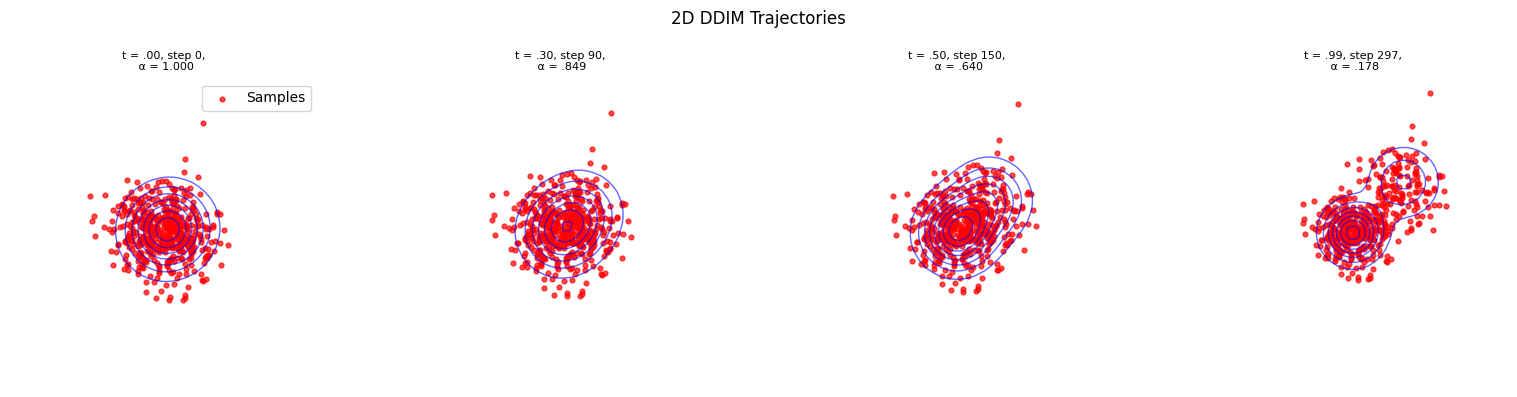
Now we demonstrate how to generate samples from the GMM distribution using numerical integration of the reverse-time SDE. We compare different integrators:
Euler-Maruyama: Stochastic integrator for the reverse SDE
DDIM: Deterministic sampling with optional stochasticity
Euler: Deterministic ODE solver with optional noise injection
The key component is the score function \(\nabla_x \log p_t(x)\), which we can compute exactly from the GMM’s closed-form density.
Generated 500 1D samples with each integrator
Generated 500 2D samples with each integrator
Euler-Maruyama
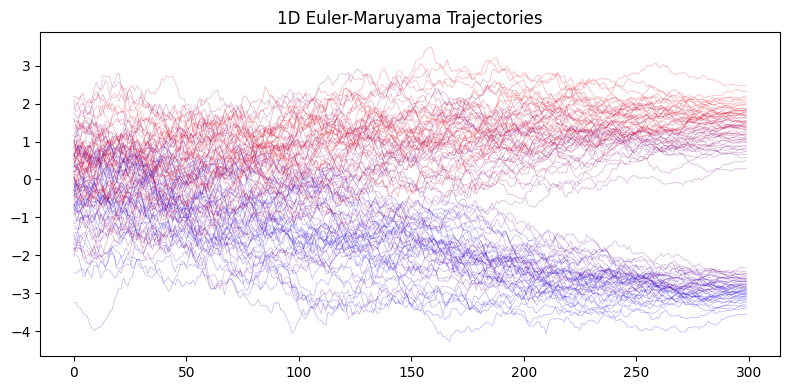
DDIM
Euler
Euler-Maruyama
DDIM
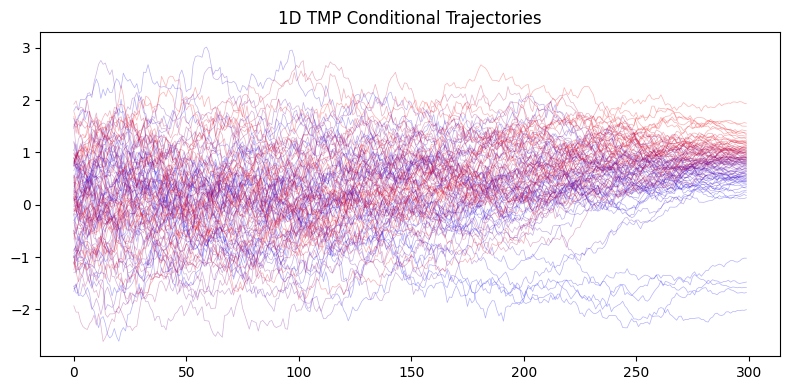
Conditional Generation#
We demonstrate conditional generation for solving inverse problems of the form \(x_0 \sim p(x_0|y)\) where \(y\) is a measurement. We show two approaches:
TMP(Tweedie’s Moment Projection): Uses the forward model during sampling to guide generation
Conditional Score: Directly uses the posterior score function \(\nabla_x \log p_t(x|y)\)
TMP Approach#
TMP (Tweedie’s Moment Projection) incorporates the measurement likelihood during the reverse diffusion process.
# Import conditional generation components
from diffuse.denoisers.cond import TMPDenoiser
from diffuse.base_forward_model import MeasurementState
from diffuse.examples.gaussian_mixtures.forward_models.matrix_product import MatrixProduct
from diffuse.examples.gaussian_mixtures.cond_mixture import compute_xt_given_y
forward_model_1d = MatrixProduct(A=A_1d, std=sigma_y_1d)
measurement_state_1d = MeasurementState(y=y_observed_1d, mask_history=A_1d)
# Create TMP denoiser for conditional generation
tmp_denoiser_1d = TMPDenoiser(
integrator=euler_m_integrator,
model=sde,
predictor=predictor_1d,
forward_model=forward_model_1d,
x0_shape=(1,),
)
# Generate conditional samples
key_cond_1d = jax.random.PRNGKey(789)
cond_state_1d, cond_hist_1d = tmp_denoiser_1d.generate(
key_cond_1d,
measurement_state_1d,
n_steps,
n_samples,
keep_history=True,
)
print(f"Generated {n_samples} 1D conditional samples using TMP")
print(f"1D Conditional samples x mean: {jnp.mean(cond_state_1d.integrator_state.position):.3f} (target: {y_observed_1d[0]})")
Generated 500 1D conditional samples using TMP
1D Conditional samples x mean: 0.737 (target: 0.5)
Generated 500 2D conditional samples using TMP
2D Conditional samples x₁ mean: 1.393 (target: 1.5)
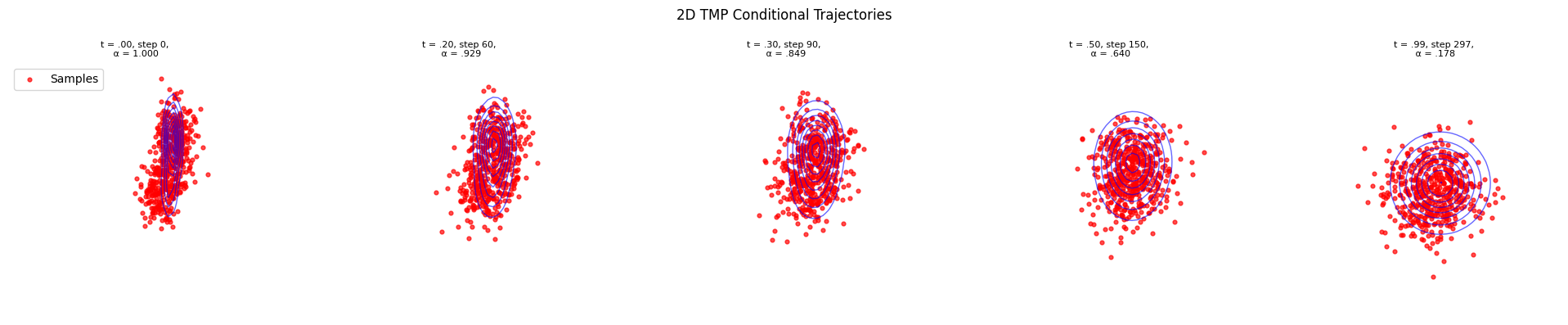
Conditional Score Approach#
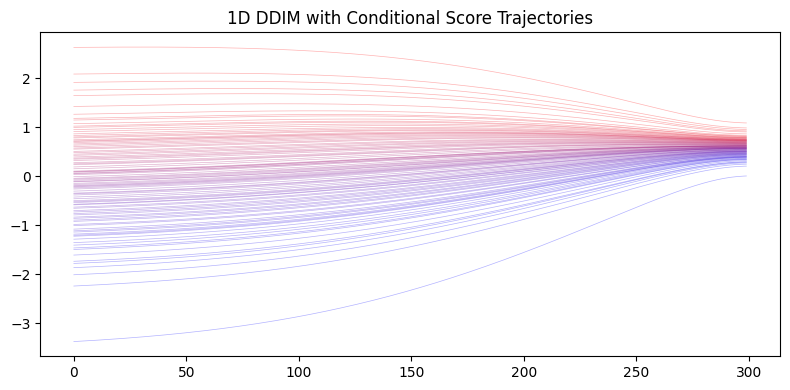
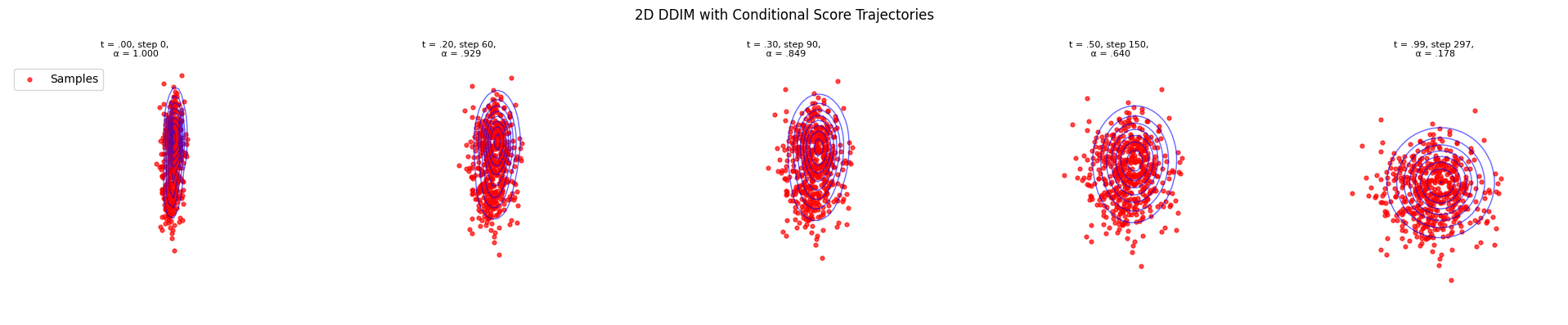
An alternative approach is to directly compute the posterior score function \(\nabla_x \log p_t(x|y)\) in closed form (since we have analytical expressions for GMMs), and use it with standard sampling methods like DDIM.
Generated 500 1D conditional samples using conditional score with DDIM
Generated 500 2D conditional samples using conditional score with DDIM
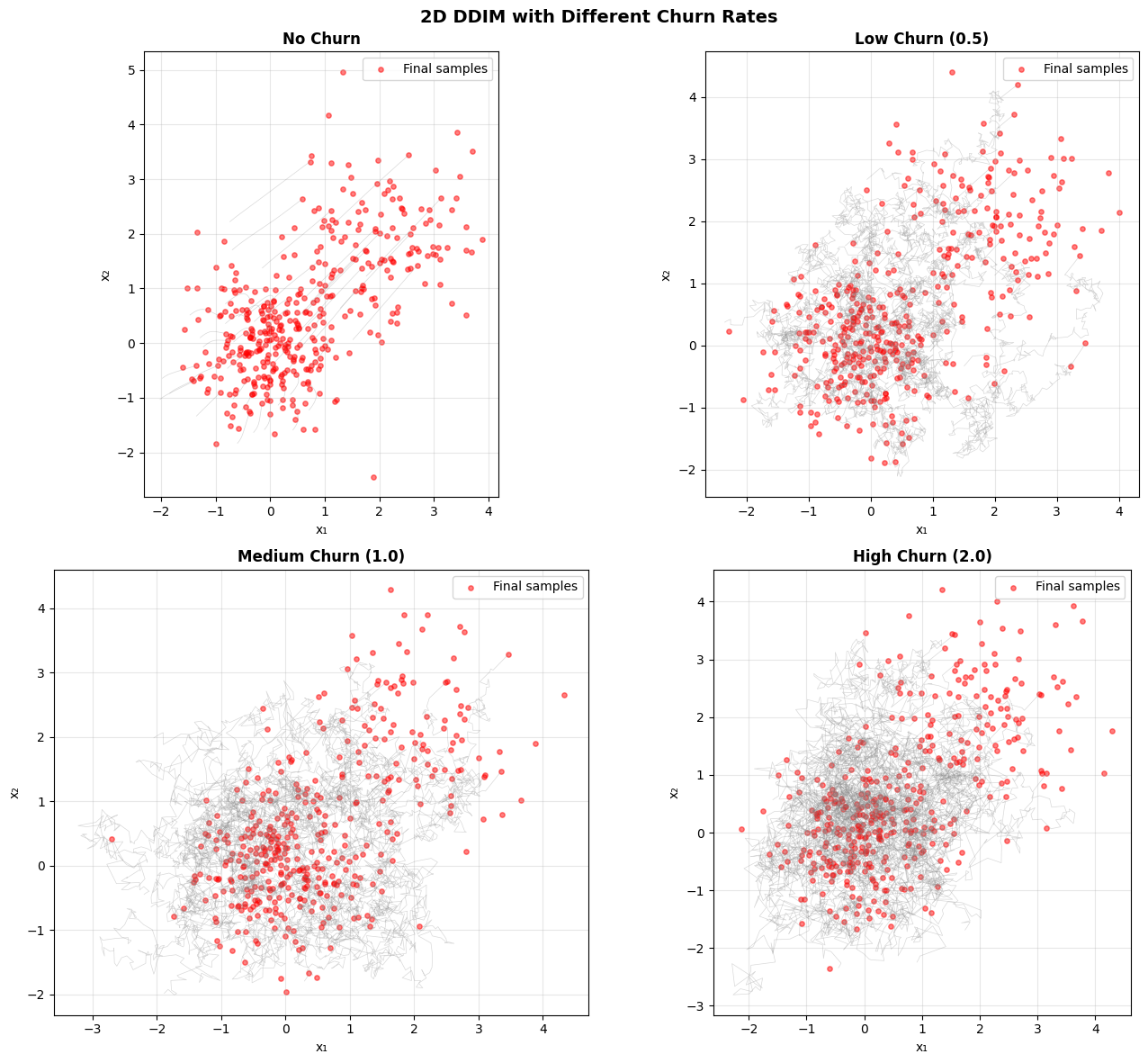
Stochastic Churn#
Deterministic samplers such as DDIM or Euler can optionally be enhanced with stochastic churning, a mechanism that injects controlled noise at selected time steps to improve sample diversity and exploration. In this section, we explain how stochastic churn works and how it modifies the diffusion sampling process.
Stochastic churn proceeds in three steps:
Compute a new noise level based on the current time and churning schedule
Rescale the sample according to the updated signal–noise ratio
Inject Gaussian noise scaled by a user-defined factor
The churn update is given by:
Where:
\(\alpha\) and \(\alpha_{\text{churned}}\) come from the diffusion model’s noise schedule
\(\varepsilon \sim \mathcal{N}(0, I)\) (standard Gaussian noise)
noise_factorscales the injected stochastic correction
In the following, we illustrate how to apply stochastic churning during DDIM sampling and how different churn parameters affect sample trajectories.